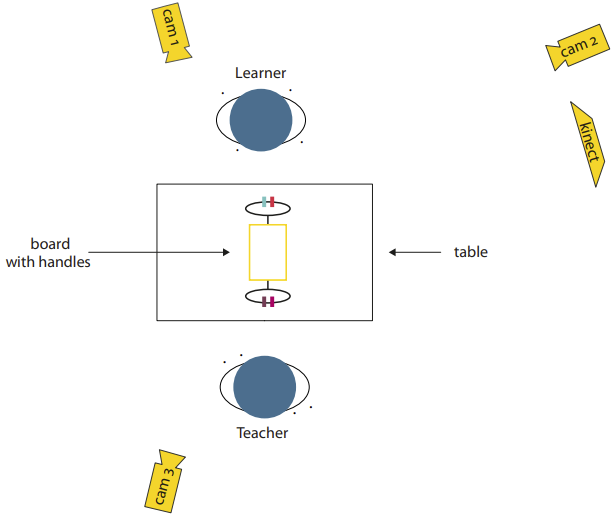
Human instructors often refer to objects and actions involved in a task description using both linguistic and non-linguistic means of communication. Hence, for robots to engage in natural human-robot interactions, we need to better understand the various relevant aspects of human multi-modal task descriptions. We analyse reference resolution to objects in a data collection comprising two object manipulation tasks (22 teacher student interactions in Task 1 and 16 in Task 2) and find that 78.76% of all referring expressions to the objects relevant in Task 1 are verbally underspecified and 88.64% of all referring expressions are verbally underspecified in Task 2. The data strongly suggests that a language processing module for robots must be genuinely multi-modal, allowing for seamless integration of information transmitted in the verbal and the visual channel, whereby tracking the speaker’s eye gaze and gestures as well as object recognition are necessary preconditions.
@article{grossetal16is,
title={Multi-modal referring expressions in human-human task descriptions and their implications for human-robot interaction},
author={Gross, Stephanie and Krenn, Brigitte and and Scheutz, Matthias},
year={2016},
journal={Interaction Studies},
volume={17},
issue={17},
pages={180--210}
url={https://hrilab.tufts.edu/publications/grossetal16is.pdf}
doi={10.1075/is.17.2.02gro}
}